python train_test_split drop 2 columns|python test train dataframe : Chinese I'm trying to set up a test_train_split with data I have read from a csv into a pandas dataframe. The book I am reading says I should separate into x_train as the data and y_train as the . 10 horas atrás · stephany ribeiro nude. HD admin10 2:57 Alicya Ribeiro algemada sendo penetrada no cu e na buceta por brinq. HD admin10 2:09 Putaria lésbica na lavanderia usando brinquedinho a modelo Alicya R. ADS 57100 Esta e sua chance de ganhar o jackpot. Gire para ganhar!
{plog:ftitle_list}
webArgentinos Juniors II. 02 Nov 2023. Copa de la Superliga Reservas. Colón II. 19 NOV. Vélez Sarsfield II. dentro de 1 mes. Confira todo o calendário de partidas e resultados de Vélez Sarsfield II. Além de resultados desta temporada, você encontrará o .
continental aircraft engine compression test
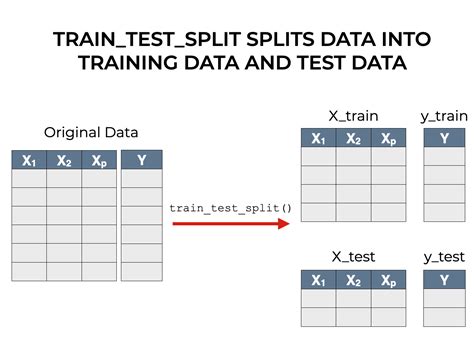
test train split dataframe
I'm trying to set up a test_train_split with data I have read from a csv into a pandas dataframe. The book I am reading says I should separate into x_train as the data and y_train as the . The train_test_split function from the sklearn library is a popular choice for this task. However, in some cases, it is necessary to stratify the data based on multiple columns to ensure a representative distribution in both the . Consider a dataframe that contains two columns, text and label. I can very easily create a stratified train-test split using sklearn.model_selection.train_test_split. The only .
sklearn train test split python
Split arrays or matrices into random train and test subsets. Quick utility that wraps input validation, next(ShuffleSplit().split(X, y)) , and application to input data into a single call for .
In this tutorial, you’ll learn: Why you need to split your dataset in supervised machine learning. Which subsets of the dataset you need for an unbiased evaluation of your model. How to use train_test_split() to split your .You could just use sklearn.model_selection.train_test_split twice. First to split to train, test and then split train again into validation and train. Something like this: X_train, X_test, y_train, y_test. = train_test_split(X, y, test_size=0.2, .
In this tutorial, you’ll learn how to split your Python dataset using Scikit-Learn’s train_test_split function. You’ll gain a strong understanding of the importance of splitting your data for machine learning to avoid underfitting or . You can use the train_test_split function from the sklearn.model_selection module. Here’s a simple example: from sklearn.model_selection import train_test_split X_train, X_test, y_train, .
In Python, train_test_split is a function in the model_selection module of the popular machine learning library scikit-learn. This function is used to perform the train test split . When working with machine learning models, it is crucial to split the data into training and testing sets to evaluate the model’s performance. The train_test_split function from the sklearn library is a popular choice for this . Scikit learn plays really well with Pandas, so I suggest you use it. Here's an example: In [1]: import pandas as pd import numpy as np from sklearn.model_selection import train_test_split data = np.reshape(np.random.randn(20),(10,2)) # 10 training examples labels = np.random.randint(2, size=10) # 10 labels In [2]: # Giving columns in X a name X = .train_test_split()是sklearn.model_selection中的分离器函数,⽤于将数组或矩阵划分为训练集和测试集,函数样式为: X_train, X_test, y_train, y_test = train_test_split(train_data, train_target, test_size, random_state,shuffle)
The train_test_split function returns a Python list of length 4, where each item in the list is x_train, x_test, . It has two columns: Q and S, but since we’ve already removed one other column . This means that we can now drop the original Sex and Embarked columns from the DataFrame. There are also other columns (like Name, .Doesn't stratify need at least two samples per class?train_test_split(ml, train_size=0.9, stratify=ml.Item_id) gives ValueError: The least populated class in y has only 1 member, which is too few.The minimum number of groups for any class cannot be less than 2.. i.e. how can it split data in two groups keeping stratification if there is only one element to split? In this article, let's learn how to do a train test split using Sklearn in Python. Train Test Split Using Sklearn The train_test_split() method is used to split our data into train and test sets. First, we need to divide our data into features (X) and labels (y). The dataframe gets divided into X_train,X_test , y_train and y_test. X_train and y_tra Step 4: Use the train test split class to split data into train and test sets: Here, the train_test_split() class from sklearn.model_selection is used to split our data into train and test sets where feature variables are given as input in the method. test_size determines the portion of the data which will go into test sets and a random state is used for data reproducibility.
The Sklearn train_test_split function helps us create our training data and test data. This is because typically, the training data and test data come from the same original dataset. To get the data to build a model, we start with a single dataset, and then we split it into two datasets: train and test. If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to keep track of the indices (remember to fix the random seed to make everything reproducible):. import numpy # x is your dataset x = numpy.random.rand(100, 5) numpy.random.shuffle(x) training, test = x[:80,:], x[80:,:] why do we drop target/label before splitting data into test and train? for example in code below. X = df.drop('Scaled sound pressure level',axis=1) y = df['Scaled sound pressure level'] split the data. from sklearn.model_selection import train_test_split 80/20 split by fixing the seed to reproduce the results You can simply do it with train_test_split() method available in Scikit learn: from sklearn.model_selection import train_test_split train, test = train_test_split(X, test_size=0.25, stratify=X['YOUR_COLUMN_LABEL']) I have also prepared a short GitHub Gist which shows how stratify option works:
you want all categories from all categorical variables to be in your train split. Using : train, test = train_test_split(Meta, test_size = 0.2, stratify=Meta[["Method", "Type"]]) ensure that all categories are in the train split and test split. This is more than what you want.
Thanks @MaxU. I'd like to mention 2 things to keep things simplified. First, use np.random.seed(any_number) before the split line to obtain same result with every run. Second, to make unequal ratio like train:test:val::50:40:10 use [int(.5*len(dfn)), int(.9*len(dfn))].Here first element denotes size for train (0.5%), second element denotes size for val (1-0.9 = 0.1%) and . My question is rather close to How to create a train_test_split based on a conditional in python. but I am looking for a better solution. I have a pandas dataframe where I would typically use the train_test_split function. X_train, X_test, y_train, y_test = train_test_split(data[xvars], data[yvar], train_size=0.98, random_state=42)
from sklearn.model_selection import train_test_split . There are a couple of arguments we can set while working with this method - and the default is very sensible and performs a 75/25 split. In practice, all of Scikit-Learn's . test_size: This parameter represents the proportion of the dataset that should be included in the test split. The default value for this parameter is set to 0.25, meaning that if we don’t specify the test_size, the resulting split . Train test split based on a column values - sequentially. Ask Question Asked 5 years, . *0.6).astype(int)# get the top 60% of each group Train=df.loc[s==0].copy() Test=df.drop(Train.index) Train Out[118]: Col1 Col2 Col3 y 0 A -2.21 -0.270 -1 1 B -9.59 -0.570 1 2 B 0.16 0.072 -1 3 A 1.29 -0.150 -1 4 B -31.92 -0.210 -1 6 A 15.23 -1.060 1 Test .Split. The train_test_split() function creates train and test splits if your dataset doesn’t already have them. This allows you to adjust the relative proportions or an absolute number of samples in each split. In the example below, use the test_size parameter to create a test split that is 10% of the original dataset:
The train-test split procedure is used to estimate the performance of machine learning algorithms when they are used to make predictions on data not used to train the model. It is a fast and easy procedure to perform, the results of which allow you to compare the performance of machine learning algorithms for your predictive modeling problem. When fitting machine learning models to datasets, we often split the dataset into two sets:. 1. Training Set: Used to train the model (70-80% of original dataset) 2. Testing Set: Used to get an unbiased estimate of the model performance (20-30% of original dataset) In Python, there are two common ways to split a pandas DataFrame into a training set and .
sklearn train test split
After the splitting of my data, im trying a feature ranking but when im trying to access the X_train.columns im getting this 'numpy.ndarray' object has no attribute 'columns'. from sklearn.
scikit learn train test split
sklearn.model_selection has several other options other than train_test_split.One of them, aims at solving what you're after. In this case you could use GroupShuffleSplit, which as mentioned inthe docs it provides randomized train/test indices to split data according to a third-party provided group.You also have GroupKFold for these cases which is very useful. What Is the Train Test Split Procedure? Train test split is a model validation procedure that allows you to simulate how a model would perform on new/unseen data. Here is how the procedure works: Train test split procedure. | Image: Michael Galarnyk . 1. Arrange the Data. Make sure your data is arranged into a format acceptable for train test . Photo by Markus Winkler from Pexels. Machine Learning is teaching a computer to make predictions (on new unseen data) using the data it has seen in the past. Machine Learning involves building a .
Let's see how to split a text column into two columns in Pandas DataFrame. Method #1 : Using Series.str.split() functions. Split Name column into two different columns. By default splitting is done on the basis of single space by str.split() function. # import Pandas as pd import pandas as pd # create a new data frame df = pd.DataFrame({'Name': ['J
continental compression test
sklearn.model_selection has several other options other than train_test_split.One of them, aims at solving what you're asking for. In this case you could use GroupShuffleSplit, which as mentioned inthe docs it provides randomized train/test indices to split data according to a third-party provided group.This is useful when you're doing cross-validation, and you want to . The Basics: Sklearn train_test_split. The train_test_split function is a powerful tool in Scikit-learn’s arsenal, primarily used to divide datasets into training and testing subsets. This function is part of the sklearn.model_selection module, which contains utilities for splitting data. But how does it work? Let’s dive in. from sklearn.model_selection import train_test_split .
continental compression test service bulletin
WEBEnjoy the videos and music you love, upload original content, and share it all with friends, family, and the world on YouTube.
python train_test_split drop 2 columns|python test train dataframe